学部別インデックス
理工学部・データサイエンス学科
松田 眞一
| 職名 | 教授 |
|---|---|
| 専攻分野 | 統計学 |
| 主要著書・論文 | “混合系直交配列表における交互作用の交絡の可視化と応答曲面への応用”、共著、『日本経営工学会論文誌』、第68巻第4号、244~250頁、2018年1月 |
| 将来的研究分野 | 多重比較 |
| 担当の授業科目 | 「数理技術実習」「ビッグデータのための統計」「統計データ解析法」 |
食べ物の好みを探る
(1)「数理技術実習」の概要
データサイエンス学科の必修科目「数理技術実習」はORと統計学に関するPCを用いた実習を行います。私はそのうち統計学を担当しています。統計学は実際に得られた数値データを分析して、なんらかの情報を読み取る学問ですので、理論ばかりを勉強していても面白くありません。(もちろん、それはそれで重要なんですけどね。)この授業ではデータを扱うとはどういうことであるかという話から始めて、実際に計算機を使ってもらいながら理論で学んだ統計学を実践してもらいます。
(2)講義内容の一例
男女の各年齢層における25種類の食品の嗜好に関するデータについて解析した結果を紹介しましょう。下図はデータを主成分分析(Principal component analysis)といわれる方法で分析した結果です。
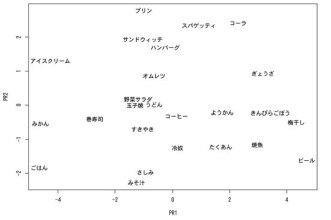
Principal component analysis
この図の横軸のPR1というのは男女各年齢層(全部で10グループ)のデータから最も食品が区別しやすいように解析して導き出されたもので、第1主成分と呼ばれています。この軸にどんな意味があるのかを考えるのは難しいのですが、結果だけ述べるとマイナスに行けば行くほど性別や年齢に関係なくみんなに好かれている食品を表していることが分かります。最も左に位置する「ごはん」や「みかん」はその典型と言えるでしょう。
一方、縦軸のPR2(第2主成分)というのはPR1で説明できなかった違いのうち最も意味のある方向を抜き出したものになります。やはり結論だけ述べるとマイナスに行けば行くほど大人に好かれている食品ということが分かります。上の方に位置する「プリン」や「コーラ」や「スパゲッティ」などは子供に好かれる食品だというわけです。元の10次元のデータでは視覚的に捉えることが困難だったのですが、主成分分析を用いて2次元化することで大変分かりやすくなりました。